
The Architecture Behind your Login
Architecting Scalable Login Systems: A Comparative Deep Dive


Most of us are logging in to web applications every day. In fact, I hope you are logged into your email account right now. If not please consider subscribing and receiving a monthly tech article for free! ;)
In this blog post, I will outline common approaches for designing the architecture behind a login process. I will share insights from evolving an initial, simple design towards a highly scalable solution. I put a lot of emphasis on the user session since its design impacts the scalability and security of the entire architecture.
The Login Flow
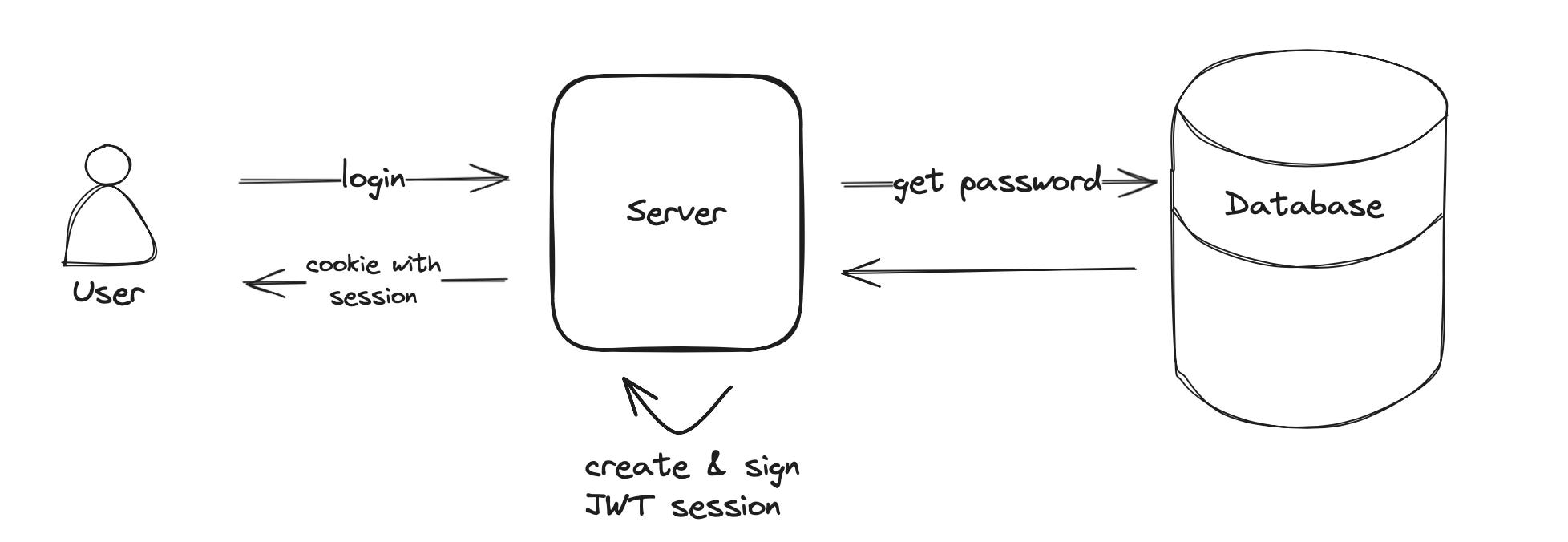
When you log in to a web application you enter an email and password to authenticate. During the authentication, the server will compare the provided credentials with the registered username and password hash stored in the database. If authentication succeeds a user session is created and access to the application can be granted.
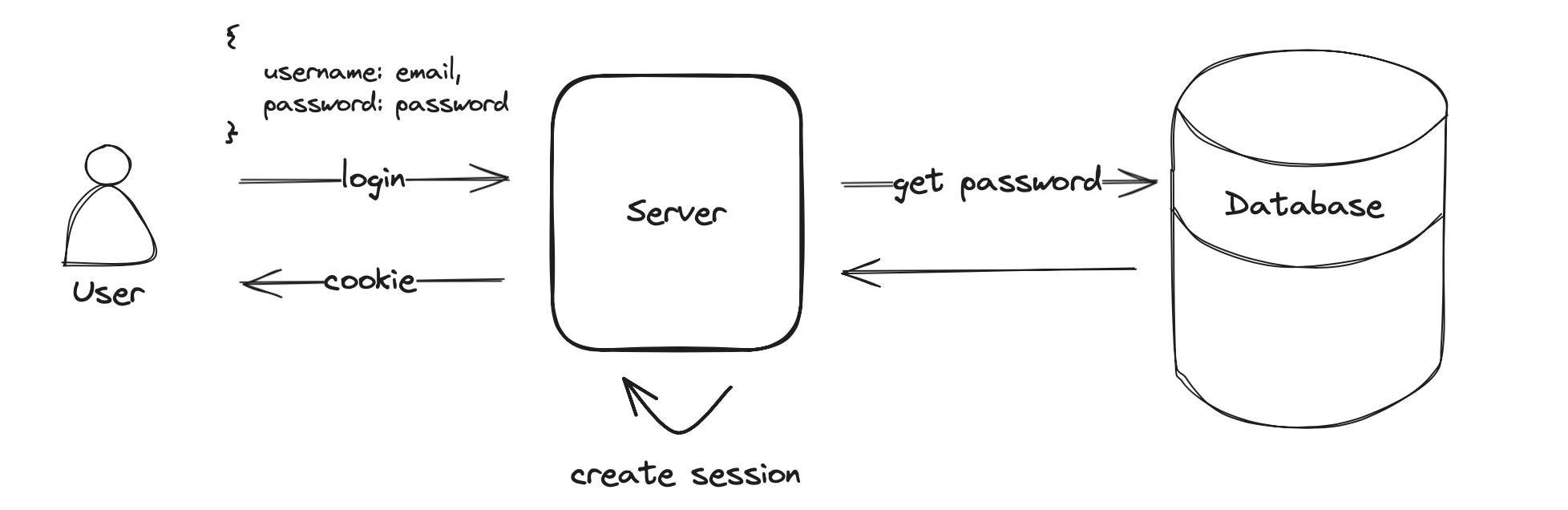
Why do we need a user session?
When you browse the internet you are using HTTP to communicate with the server. As the protocol is stateless it does not remember your login status when you navigate to the next page or click a button. Wouldn’t it be awful if you would have to re-authenticate for every action?
This is exactly what the session solves - it stores the user state so you don’t have to log in again. The server will create a session and send a cookie in the response. The cookie contains a unique identifier and will be sent by your browser for every subsequent request. This allows the server to identify you as already authenticated.
The following sections will compare alternative architectures as sessions can be stored on the server or client side.
Server Side Session
While storing sessions on the server side is widely adopted it can be implemented in different ways.
Sticky Session
Sessions can be stored on the server directly in memory if sticky session routing is configured on the load balancer. With sticky sessions enabled the load balancer will consistently route requests based on the cookie to the same backend server. Hence your user session is stored in memory on a single server but unavailable on any other.
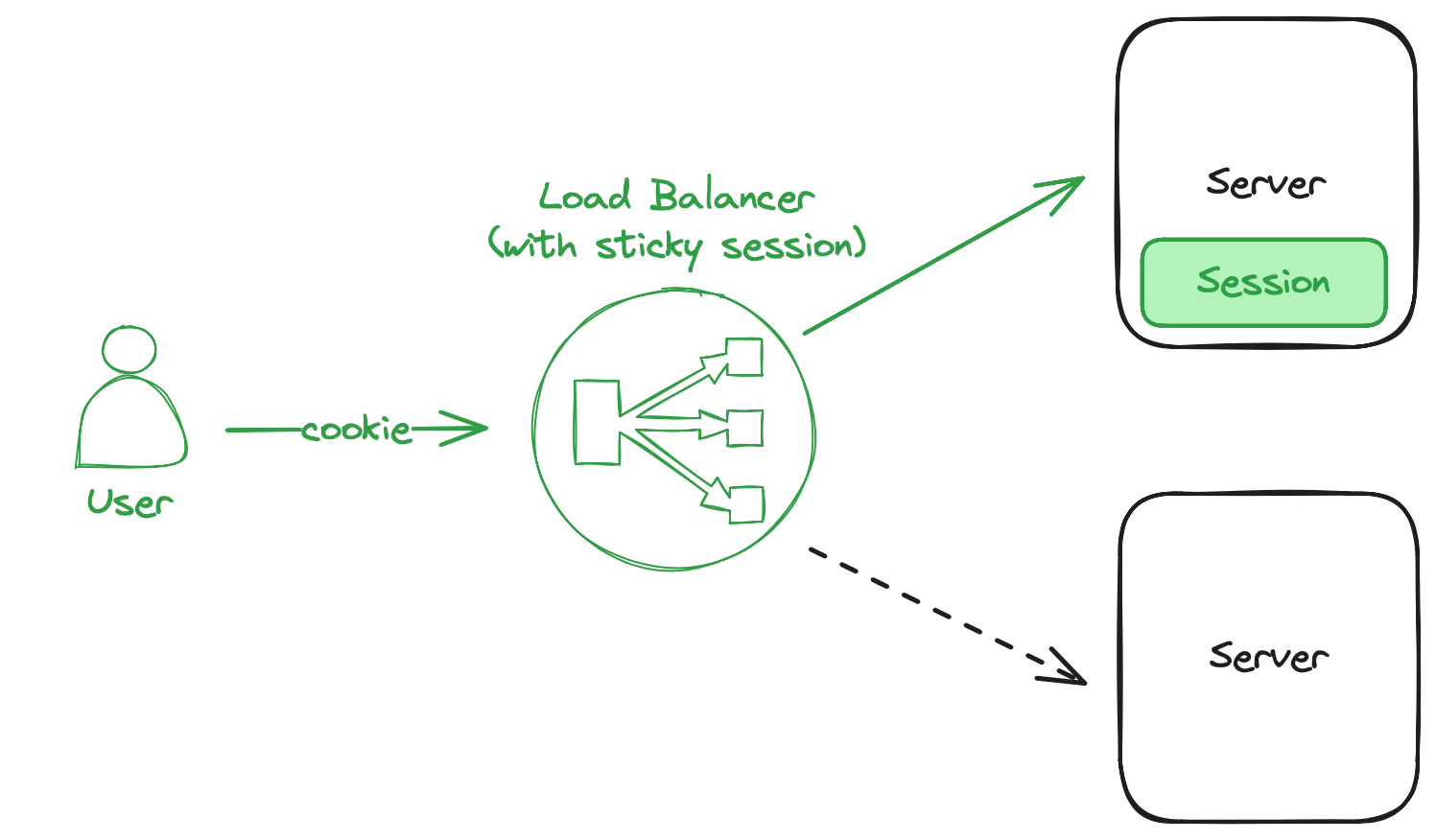
Sticky sessions are an easy way to bootstrap the login flow and can be attractive for smaller startups or scenarios with consistent throughput. This approach does not require configuring or paying for extra storage, since sessions are kept in memory on the server. The implementation is straightforward since most load balancers support request routing based on cookies out of the box. Similarly common authentication frameworks support storage of sessions in memory.
After running with sticky sessions for some time I experienced its limitations firsthand:
loss of session data: Memory is an ephemeral storage. Application release, horizontal server scale-in, and server failure will cause session loss. The result is a poor user experience since the user has to authenticate again in case of such events.
spiky throughput: An automated, horizontal scale-out event adds server capacity behind the load balancer to handle increasing user traffic. Sticky sessions will prevent user traffic from being distributed equally between all servers. Instead, all existing users that have logged in before will keep being forwarded to the old, existing servers. On the one hand, a new server will stay idle as only a fraction of the traffic will be forwarded to them. Only the traffic from users logged in after the scale-out event will eventually be sent to the new server. On the other hand old servers will remain with a high utilization. High utilization causes latency and error rates to increase. In the worst case, the web application can become unavailable for some users.
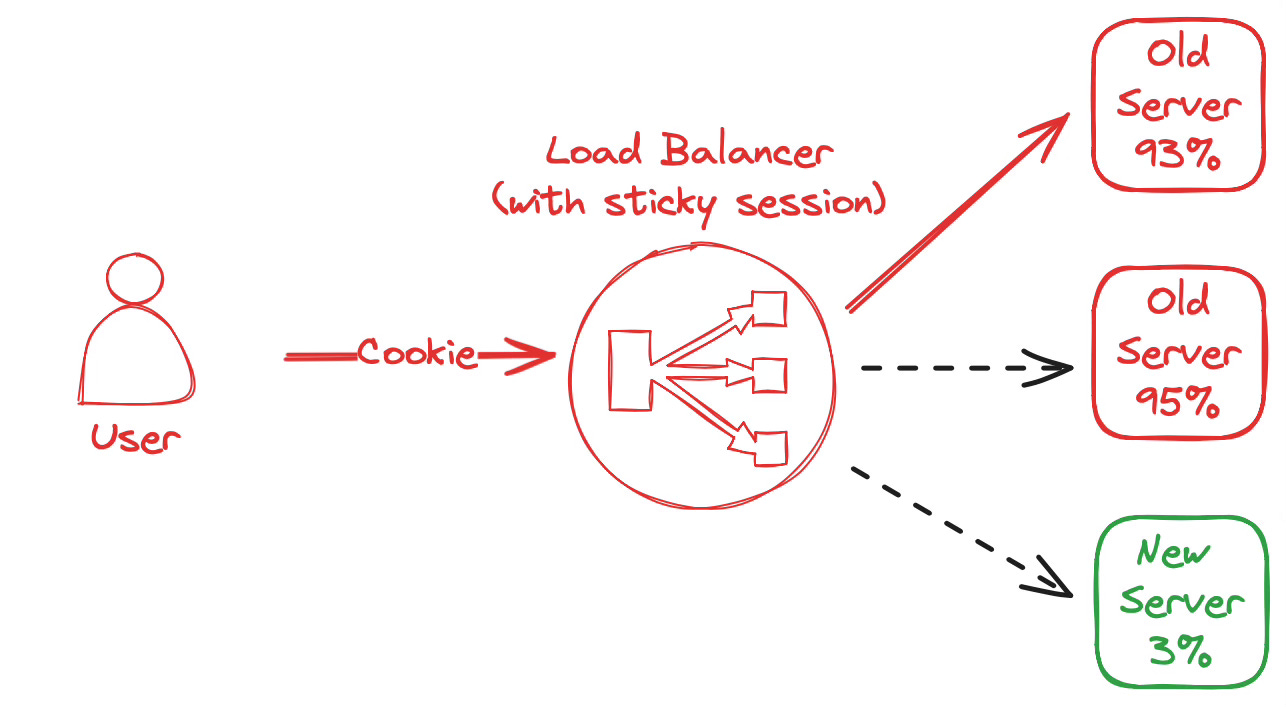
Centralized Server Storage
Due to a growing user base and the need to scale our application, we had to remove sticky sessions. By introducing a centralized storage the servers don’t have to keep the session in memory, but instead query the cache for the user session based on the identifier in the cookie. Common session storages are low latency caches like Redis and Memcached. The cache should be set up in a highly available configuration to avoid creating a single point of failure in the architecture.
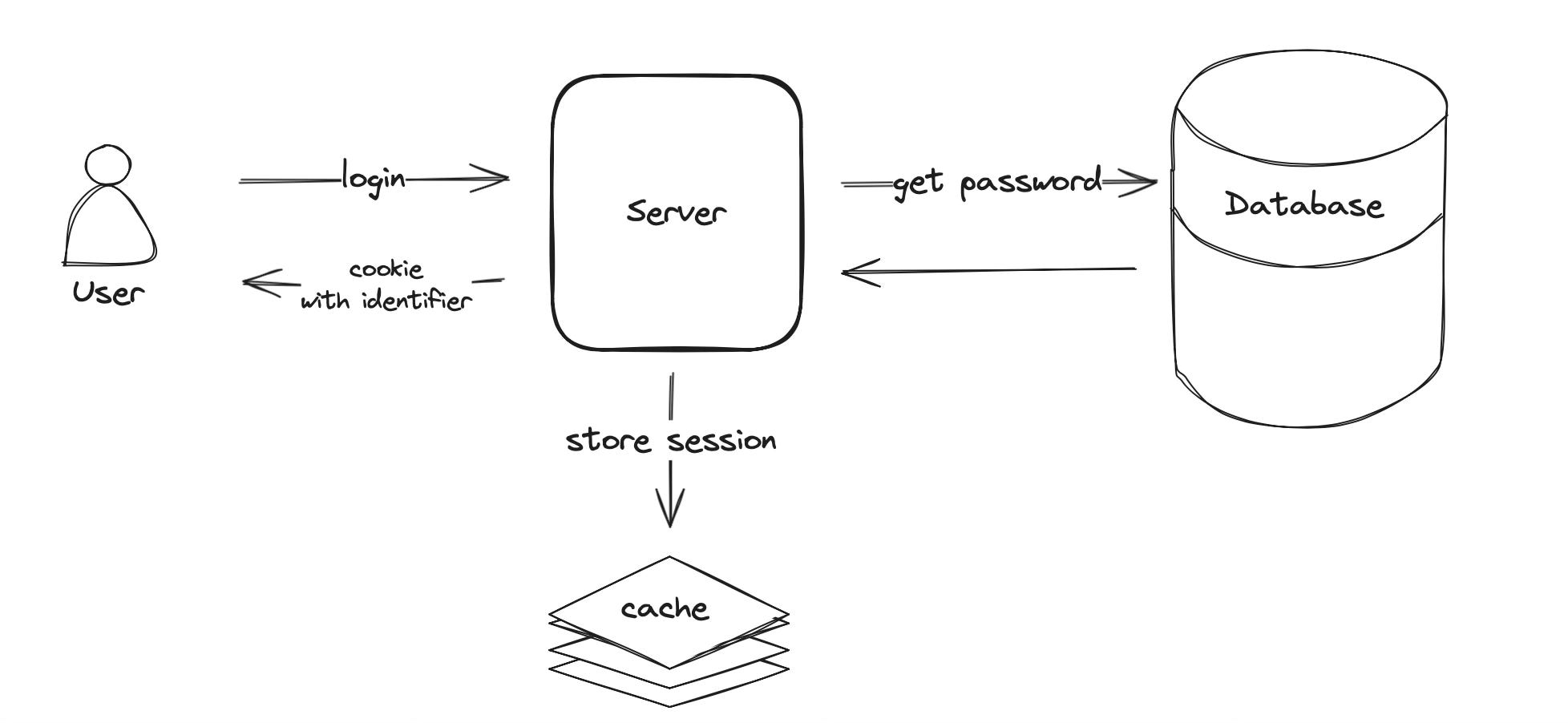
Removing sticky sessions enabled us to use the round-robin algorithm on the load balancer and to distribute the traffic equally across all servers. Now server utilization is dynamically controlled by adding or removing servers without any session loss.
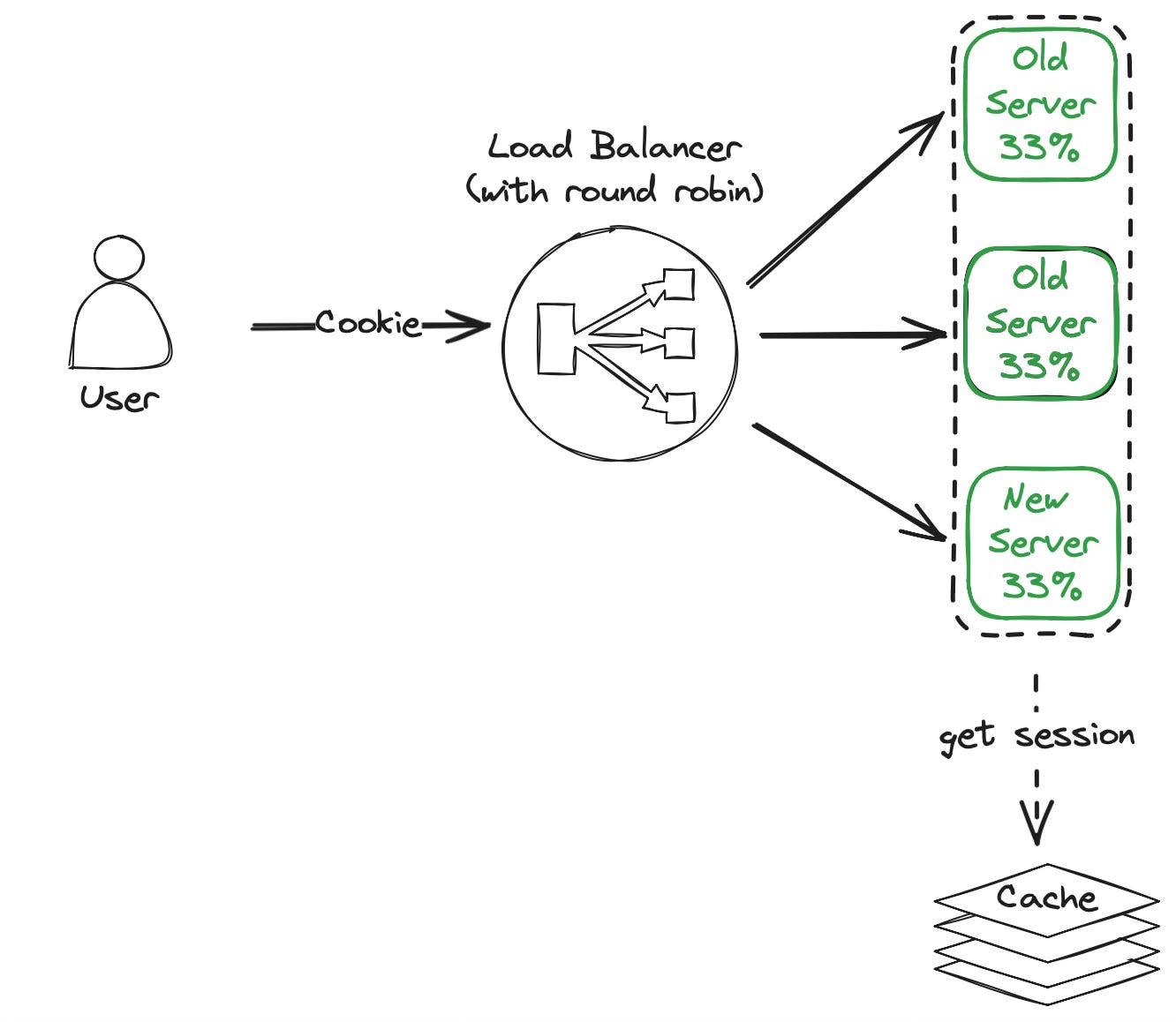
The main drawback of this approach is the increased cost required for the cache infrastructure. Be aware that the maximum throughput of UI traffic is now limited by what the cache can handle (which is a lot for modern caches).
Client Side Session
With the increasing popularity of JSON Web Tokens (JWT) storing sessions on the client side became more common. After successful authentication, the server stores the user session into a JWT and signs the payload with a secret key. The JWT is put inside the cookie before being returned to the user. This means the entire user session is stored in your browser. Subsequent requests from the browser will contain the cookie with the session. Since the JWT is signed tampering with the session content is not possible.
This approach is stateless since the session is not stored on the backend. Stateless applications scale better since they don’t require synchronization for concurrent data access. Additionally, verifying the signature of the token is typically faster than fetching the session from centralized storage. However, there are also some downsides to client-side sessions:
revoke user access: Once a malicious attacker steals the token it should be revoked immediately. Withdrawing access for specific users is hardly possible for client-side sessions without defeating the purpose of keeping the server stateless. Hence it is best practice to keep tokens short lived. People say there are two hard problems in computer science: “cache invalidation and naming things”[1]. I would like to add a third item to that list: revoking access tokens. Different approaches exist, but go beyond the scope of this article [2].
session readable by client: Since the session is stored on the client you must not store confidential information in the session.
small session size: Cookies come with strict maximum size limits which restricts the amount of data you can store in a client session.
bandwidth consumption: Having to send the full session with every request adds some network overhead
TL;DR
Storing user sessions on the server side gives tight control over the session lifecycle and makes revoking user access easy. Therefore server-side sessions are typically chosen in domains like banking or healthcare. Client-side sessions are great for applications that prioritize scalability and low latency.
When I started working in the Identity and Access Management (IAM) domain I was looking for a quick overview of common user sessions architectures, but didn't find anything good. Hence I have summarised my learnings for you into this cheat sheet. I hope it will help you choose a suitable architecture for your specific context.

Over to you: What are your experiences with server and client side user sessions? Anything I missed?
[1] “Two hard things” in compute science
[2] Microservice Security in Action, Chapter 3: “Pitfalls of self-validating tokens and how to avoid them”